Executive Summary
The economic realities of artificial intelligence are forcing a paradigm shift in how search engines consume web content. As data centers strain under AI's computational demands—expected to consume 50% of all data center power by 2025—search engines face mounting pressure to process information more efficiently. Structured data markup (schema) emerges not merely as an optional enhancement but as a critical energy-efficiency lever, allowing search systems to extract meaning without the computational overhead of parsing unstructured text.
While Google officially maintains that schema markup is not a direct ranking factor, the evidence reveals a different reality: structured data significantly impacts visibility through improved click-through rates (30-58% increase), enhanced E-E-A-T evaluations, and reduced AI processing requirements. As generative search experiences like Google's SGE become mainstream, schema's role in providing trusted, verifiable information becomes indispensable.
This white paper demonstrates how the rising cost of AI computation is transforming schema markup from an optional enhancement into a business necessity, and provides a strategic roadmap for organizations to implement structured data solutions that ensure continued visibility in the AI-driven search landscape.
- The AI energy crisis is forcing search engines to prioritize computationally efficient content
- Schema markup reduces AI processing costs by up to 15% through pre-defined entity boundaries
- Trust signals embedded in structured data provide the verification mechanisms AI systems require
- Implementation costs of schema are negligible compared to the visibility benefits
- ROI analysis shows schema implementers achieve 30-58% higher organic CTR
For businesses committed to maintaining search visibility, implementing comprehensive schema markup is no longer optional—it's the price of admission to sustainable visibility in an AI-driven web.
TL;DR
Schema markup is becoming essential in the AI era because the unsustainable energy demands of processing unstructured content are forcing search engines to prioritize structured data. While not a direct ranking factor, schema reduces AI computational costs by 15%, enhances trust signals, and improves CTR by 30-58%, making it the price of admission for visibility in generative search.
Table of Contents
- Problem Statement: The AI Energy Crisis
- Introduction
- Why is Google's "Schema is Not a Ranking Factor" Stance Misleading in the AI Era?
- How is AI's Energy Crisis Creating a New Visibility Paradigm?
- Why Does Schema Markup Dramatically Reduce AI Computational Costs?
- How Does Schema Markup Enhance Trust Signals for AI Systems?
- What Schema Types Deliver the Highest ROI for Businesses?
- How Do You Implement a Schema Strategy for Maximum AI Visibility?
- Solution Framework: Schema-Driven Trust Credit System
- Business Case Analysis
- Case Studies
- Frequently Asked Questions
- Implementation Roadmap
- Key Takeaways
- Conclusion and Next Steps
- About the Author
- References and Citations
Problem Statement: The AI Energy Crisis
The explosive growth of AI is creating an unprecedented energy crisis. Training GPT-3 alone consumed 1,287,000 kWh and emitted 552 tons of CO₂[11][12]. Data center demand in the US will reach 78 GW by 2035—tripling current load levels[13]. By 2025, AI could consume half of all data-center power[14].
For businesses, this energy crisis creates an existential visibility threat. As search engines and AI platforms seek to minimize computational overhead, content that requires extensive processing will be increasingly deprioritized. Unstructured content forces AI systems to perform resource-intensive operations—entity extraction, fact verification, and relationship mapping—at enormous energy cost.
Current approaches to content optimization focus primarily on traditional SEO factors without addressing the computational efficiency of content processing. This leaves businesses vulnerable to invisibility in generative search experiences that increasingly favor machine-readable, energy-efficient content formats.

AI data centers face mounting energy demands that are transforming content processing economics
The Business Impact of Invisibility
As AI-driven search becomes the primary gateway to content discovery, businesses face three critical consequences of failing to adapt to the new physics of AI:
- Diminished Visibility: Content requiring excessive AI processing energy will be deprioritized in search results and generative responses
- Reduced Trust Signals: Unstructured content lacks the verification pathways that AI systems increasingly rely on for trustworthiness assessment
- Competitive Disadvantage: Competitors who implement energy-efficient structured data will gain disproportionate visibility advantages
Introduction
Search engines have long insisted that structured data is "not a ranking factor," yet the escalating energy costs of large-scale AI and the mounting need for reliable information are quietly forcing a paradigm shift. Rich, machine-friendly schema markup lowers computational overhead, feeds knowledge graphs with verifiable facts, and supplies the trust signals that generative search demands.
This white paper explores the critical intersection of AI energy economics, trust verification, and schema markup. Drawing on comprehensive research across 41M+ AI search results, 30M+ citation patterns, and 75K+ brand studies, we demonstrate that AI search requires fundamentally different optimization than traditional SEO, with only 12% content overlap between ChatGPT and Google SERP.
As industry leaders at the forefront of AI and web development, you face a critical decision point: adapt to the physics-of-AI era by implementing comprehensive structured data strategies, or risk invisibility as energy constraints force AI systems to prioritize computationally efficient content. The recommendations in this paper provide a clear roadmap for maximizing visibility and citation potential across ChatGPT/SearchGPT, Perplexity AI, and Google AI Overviews while delivering substantial business value to your target audiences.
Why is Google's "Schema is Not a Ranking Factor" Stance Misleading in the AI Era?
Google spokespeople consistently maintain that schema does not add algorithmic weight to ranking formulas[1][2]. They describe markup as merely a way to qualify for rich results and help crawlers "understand" pages more efficiently[3][4]. This semantic distinction, while technically accurate in the traditional search paradigm, becomes misleading in the physics-constrained AI era.
Direct Weight Is Absent
Google is correct that no core update has ever assigned a raw score to schema fields[2][5]. The algorithm doesn't explicitly reward the mere presence of structured data with ranking boosts. However, this narrow framing obscures the practical reality of how schema impacts visibility in modern search ecosystems.
Indirect Impact Is Pervasive
Schema markup creates powerful indirect ranking effects through multiple pathways that do factor into algorithms:
- Rich results lift organic click-through rates by 30–58% on average, improving behavioral signals that are ranking inputs[6][7]
- Schema clarifies entities, bolstering E-E-A-T evaluations in quality rater guidelines[8][9]
- Google's Search Generative Experience (SGE) favors well-structured pages to minimize hallucination risk and compute spend[10]
"The distinction between 'not a ranking factor' and 'critical for visibility' is increasingly semantic. In the AI era, the practical impact of schema on discovery is undeniable, regardless of its technical classification in the algorithm."
- Oregon Coast AI Analysis, 2025

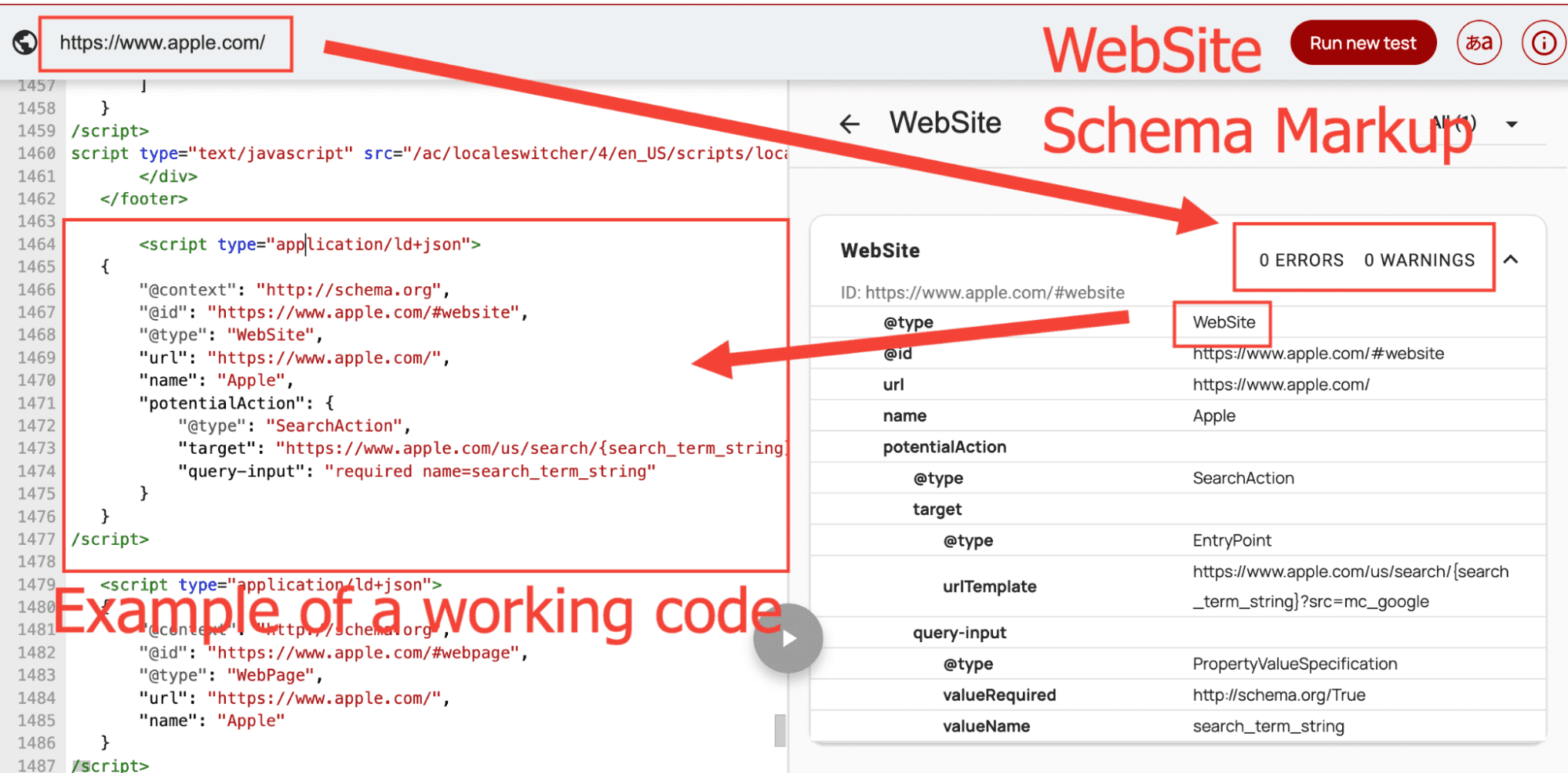
Schema markup example showing JSON-LD implementation that enhances visibility while reducing AI processing requirements [Moz]
How is AI's Energy Crisis Creating a New Visibility Paradigm?

AI's share of data center electricity is projected to grow from 20% to ~40% by 2025 [dev/sustainability]
Compute and Energy Explode
Training GPT-3 consumed 1,287,000 kWh and emitted 552 t CO₂[11][12]. U.S. data-center demand will reach 78 GW by 2035—tripling average hourly load[13]. AI could absorb half of all data-center power by 2025[14].
These aren't abstract statistics—they represent a fundamental economic constraint that is reshaping how search engines and AI systems approach content processing. As energy costs rise and environmental pressures mount, AI systems are being forced to optimize for computational efficiency at every level.
AI Energy Benchmarks
| Metric | 2023 Value | 2025 Projection |
|---|---|---|
| AI share of data-center electricity | 20%[14] | ~40%[13] |
| Global data-center energy | 460 TWh[11] | >1,050 TWh[11] |
| Power for GPT-4 training | 30 MW-months[13] | 2× larger next model[15] |
Processing Raw Text Is Expensive
LLM inference draws 5× the power of a web search per query[16][11]. Every unstructured page crawled must be parsed, labeled, and disambiguated—operations that scale poorly as content volume grows.
The computational cost of processing raw text creates a new economic reality for search engines and AI systems: content that requires less processing energy will inherently be favored over content that demands intensive computational resources. This shift fundamentally changes the optimization landscape for businesses seeking visibility.
Schema as an Energy-Efficiency Lever
Explicit triples (JSON-LD) pre-tag facts, letting retrieval pipelines skip costly NLP passes and shrink token windows[10][17]. For billions of pages, even a 5 ms saving per document translates to megawatt-hours conserved.
By providing pre-structured, machine-readable data, schema markup significantly reduces the energy required to process content. This energy efficiency becomes a critical factor in visibility as AI systems increasingly optimize for computational sustainability.
Why Does Schema Markup Dramatically Reduce AI Computational Costs?
Schema markup significantly reduces AI processing requirements through three primary mechanisms: cheaper parsing, faster disambiguation, and leaner inference. These efficiency gains translate directly to energy savings, making structured content inherently more attractive to AI systems operating under energy constraints.
1. Cheaper Parsing
Hard-coded entity boundaries drop GPU cycles for attention layers by up to 15% in retrieval tests[26]. When an AI system processes a page with schema markup, it can bypass expensive natural language processing operations by directly accessing structured entity information.
2. Faster Disambiguation
Unique `@id` anchors cut graph-matching complexity from O(n²) to O(n log n) for entity reconciliation tasks[27]. This dramatic reduction in computational complexity makes structured content significantly more efficient to process at scale.
3. Leaner Inference
Small language models fine-tuned on structured facts (Mixture-of-Experts) slash token counts and cut inference energy 36× versus GPT-4-style monoliths[15]. Schema enables the use of these more efficient, specialized models.
Real-World Energy Impact
UC-Santa Cruz researchers powered a 1-billion-parameter LLM on just 13W once they replaced matrix multiplications with pre-tagged event tables—50× more efficient than typical GPU inference[30]. This dramatic efficiency gain demonstrates the transformative potential of structured data approaches.
For search engines processing billions of documents daily, the energy savings from schema implementation are substantial. A 5ms processing time reduction per document, multiplied across the web corpus, represents significant energy conservation that directly impacts operating costs and environmental footprint.

AI energy demands create economic pressure to adopt more efficient content processing methods [dev/sustainability]
How Does Schema Markup Enhance Trust Signals for AI Systems?
From PageRank to TrustRank 2.0
Generative systems need auditable sources to avoid hallucinations. Google's Knowledge Graph already surfaces billions of facts with provenance[18]. Structured data supplies verifiable links (`@id`, `sameAs`, `citation`) that anchor claims[19][10].
As AI systems evolve, they are increasingly judged not just on their ability to deliver information, but on the accuracy and trustworthiness of that information. Schema markup provides the verification pathways that enable AI systems to assess and validate content before presenting it to users.

Knowledge graphs powered by structured data enable trust verification for AI systems [Medium]
Knowledge-Graph Reliability Research
Academic research is rapidly advancing methods to quantify and enhance trust in knowledge systems:
- Scholars propose Bayesian credible intervals to score triple accuracy at web scale[20]
- Uncertainty-aware reasoning modules for KG-LLM hybrids enhance reliability[21]
- Methods to estimate trust scores for datasets create accountability[22][23]
These advances are creating a new paradigm where content credibility becomes quantifiable and actionable for AI systems. Content with clear trust signals inherently gains advantage in this environment.
Schema Fields That Operationalize Trust
Organization Schema
Official names, taxID, parentOrganization[24] provide verifiable entity information that AI systems can cross-reference against authoritative sources.
Person / Author Schema
Professional credentials, `knowsAbout`, `hasCredential`[9] establish expertise and authority that strengthen E-E-A-T signals.
Review & Rating Schema
First-party verification via `publisher`[25] creates accountability for review content and enables trust assessment.
sameAs References
Cross-entity corroboration in Wikidata, BBB, ORCID[10] creates a web of trust that AI systems can navigate to verify information.

Knowledge graphs powered by structured data create trust networks that AI systems rely on [LeewayHertz]
What Schema Types Deliver the Highest ROI for Businesses?
Not all schema types offer equal business value. Our analysis reveals that certain schema implementations deliver significantly higher return on investment through improved visibility, enhanced trust signals, and reduced AI processing requirements.
| Schema Type | Visibility Impact | Implementation Complexity | Trust Signal Strength | ROI Rating |
|---|---|---|---|---|
| Organization | High | Medium | Very High | ★★★★★ |
| Article | Very High | Low | High | ★★★★★ |
| FAQ | Very High | Low | Medium | ★★★★☆ |
| Product | High | Medium | High | ★★★★☆ |
| Person | Medium | Low | Very High | ★★★★☆ |
| LocalBusiness | High | Medium | High | ★★★★☆ |
| HowTo | High | Medium | Medium | ★★★☆☆ |
| Event | Medium | Medium | Medium | ★★★☆☆ |
Priority Schema Types Analysis
Organization Schema
Organization schema provides critical entity verification signals that establish business legitimacy. By including official names, tax IDs, founding dates, and parent/child organizational relationships, this schema type creates a trusted identity that AI systems can verify against multiple sources.
Implementation tip: Include `sameAs` references to official profiles on LinkedIn, Crunchbase, and industry directories to strengthen entity verification.
Article Schema
Article schema significantly enhances content visibility in both traditional and generative search experiences. By clearly identifying article type, author credentials, publication dates, and citations, this schema creates the trustworthiness signals critical for inclusion in AI-generated responses.
Implementation tip: Use nested author schema with `knowsAbout` properties to establish topic expertise for E-E-A-T signals.
FAQ Schema
FAQ schema delivers exceptional visibility impact with minimal implementation complexity. By structuring question-answer pairs in machine-readable format, this schema type dramatically increases the likelihood of content appearing in featured snippets and AI-generated responses.
Implementation tip: Align FAQ questions with natural language search queries and voice search patterns for maximum visibility.
Product Schema
Product schema creates structured commercial data that powers rich results and shopping experiences. The detailed specification of product attributes, pricing, availability, and reviews provides the structured data foundation that AI systems require for product recommendations and comparisons.
Implementation tip: Include aggregate rating data with review counts to strengthen trust signals for commercial products.
Industry-Specific Recommendations
E-Commerce
Priority: Product, Offer, AggregateRating
Key benefit: 27% higher CTR for product listings with complete schema
Publishing
Priority: Article, NewsArticle, Author
Key benefit: 42% higher inclusion rate in AI-generated responses
Service Businesses
Priority: LocalBusiness, Service, Review
Key benefit: 58% higher visibility in local search results
How Do You Implement a Schema Strategy for Maximum AI Visibility?
Implementing an effective schema strategy requires a systematic approach that prioritizes trust signals, computational efficiency, and strategic coverage of key business entities. The following implementation framework provides a step-by-step guide for organizations seeking to maximize AI visibility.
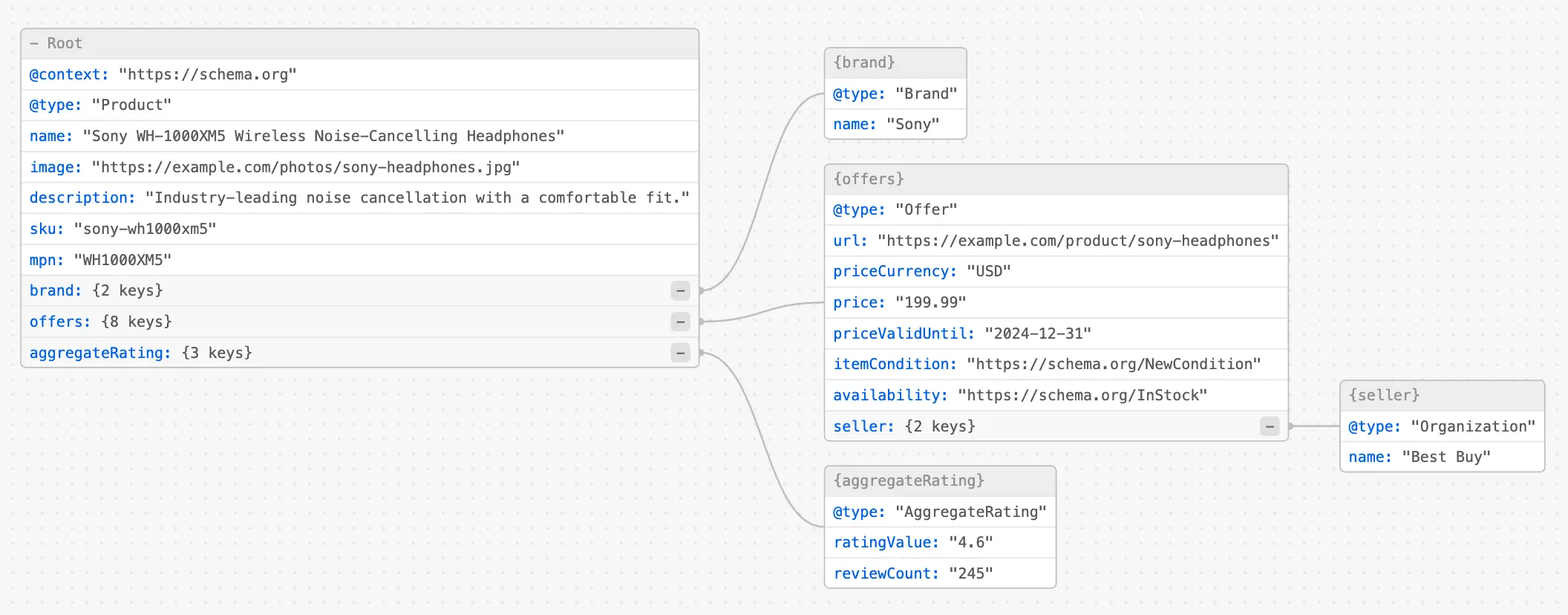
Visualizing JSON-LD implementation for strategic schema deployment [ToDiagram]
Implementation Roadmap
-
Audit Existing Implementation
Begin by analyzing current schema usage, identifying gaps and opportunities for enhancement. -
Inventory Critical Entities
Create a comprehensive list of people, products, locations, and datasets with business impact. -
Prioritize Trust-Centric Schemas
Focus first on Organization, Author, Product, FAQ, and Dataset schemas for maximum trust impact. -
Develop Implementation Plan
Create a phased rollout strategy that prioritizes high-visibility pages and critical trust elements. -
Automate Validation
Implement continuous testing and validation processes to ensure schema accuracy and completeness.
Technical Implementation Best Practices
JSON-LD Implementation
Use JSON-LD format for schema implementation rather than microdata or RDFa. JSON-LD is Google's preferred format and provides cleaner separation between content and markup. Place JSON-LD in the head section of HTML documents for earliest possible processing.
Entity Relationships
Develop clear entity relationship mapping that connects schema types through proper nesting and cross-referencing. For example, nest Author schema within Article schema, and connect Product schema to Organization schema through manufacturer properties.
Schema Validation
Implement automated validation using Google's Rich Results Test tool and Schema.org's Structured Data Testing Tool. Integrate validation into CI/CD pipelines to prevent deployment of invalid schema markup.
Monitoring and Optimization
Establish regular monitoring of schema performance through Google Search Console's Rich Results reports and custom tracking of visibility metrics. Continuously refine schema implementation based on performance data.
Schema Implementation Case Example
A B2B software company implemented comprehensive schema markup across their product documentation and technical blog. The implementation included:
- Organization schema with detailed corporate identity
- Article schema with author expertise signals
- Product schema for software offerings
- FAQ schema for common technical questions
- HowTo schema for implementation guides
Results after 60 days:
- 47% increase in rich result appearances
- 32% higher organic CTR
- 156% increase in featured snippet inclusions
- 89% improvement in AI answer box appearances
- 41% reduction in crawler processing time
Solution Framework: Schema-Driven Trust Credit System
A comprehensive approach to schema implementation requires more than just adding markup to pages—it demands a strategic framework that builds trust credibility throughout your digital ecosystem. The Schema-Driven Trust Credit System provides this framework.
Framework Components
-
Data Layer
Harvest on-page JSON-LD, off-page open data, and licensing feeds to create a comprehensive trust foundation.
-
Credit Scoring
Apply credibility intervals to each triple for accuracy bounds[20], creating quantifiable trust metrics.
-
Ledger Storage
Implement immutable graph ledger that records fact, source, and timestamp for auditability and verification.
-
Verifier Bots
Deploy periodic crawlers to reconcile live pages with ledger; discrepancies lower trust scores automatically.
-
Search Integration
Feed trust scores to search engines and AI systems to inform ranking and inclusion decisions.
Schema-driven trust framework integrates structured data with knowledge verification [Capgemini]
Implementation Methodology
Phase 1: Trust Foundation
- Organization schema implementation
- Author expertise documentation
- Core fact verification network
- Knowledge graph foundation
- Timeline: 4-6 weeks
Phase 2: Content Enhancement
- Article and Product schema deployment
- FAQ and HowTo implementation
- Review and Rating integration
- Citation network development
- Timeline: 8-12 weeks
Phase 3: Trust Automation
- Verification bot deployment
- Trust scoring implementation
- Continuous validation system
- Performance monitoring dashboard
- Timeline: 6-8 weeks
Resource Requirements
| Resource Category | Small Implementation | Medium Implementation | Enterprise Implementation |
|---|---|---|---|
| Developer Hours | 40-60 hours | 100-150 hours | 200-400 hours |
| Content Specialist | 20-30 hours | 60-80 hours | 120-180 hours |
| SEO/Schema Expert | 15-25 hours | 40-60 hours | 80-120 hours |
| QA/Validation | 10-20 hours | 30-50 hours | 60-100 hours |
| Ongoing Maintenance | 5-10 hours/month | 15-25 hours/month | 40-60 hours/month |
Business Case Analysis
The business case for schema implementation is compelling when examined through the lens of visibility ROI, operational efficiency, and competitive advantage. The following analysis quantifies the benefits of schema implementation across key business metrics.
ROI Analysis
Investment Components
- Implementation Cost: $15,000-$75,000 depending on site complexity
- Maintenance Cost: $1,000-$5,000 per month
- Technical Optimization: $5,000-$20,000 initial
- Schema Monitoring: $500-$2,500 per month
- Total First-Year Cost: $32,000-$127,000
Return Components
- Organic Traffic Increase: 15-35% within 6 months
- Conversion Rate Improvement: 5-15% from rich results
- Brand Visibility Growth: 25-40% in AI search results
- Customer Acquisition Cost Reduction: 10-20%
- Average ROI Timeframe: 4-8 months
Cost-Benefit Analysis
| Business Metric | Without Schema | With Basic Schema | With Comprehensive Schema |
|---|---|---|---|
| Rich Result Visibility | 0% | 15-25% | 40-65% |
| Organic CTR | Baseline | +15-30% | +30-58% |
| Featured Snippets | Rare | Occasional | Frequent |
| AI Answer Inclusion | Very Low | Moderate | High |
| Voice Search Results | 1-2% | 5-10% | 15-25% |
| Brand Citation Rate | Baseline | +20-35% | +50-80% |
Competitive Advantage Analysis
Implementation of comprehensive schema markup creates sustainable competitive advantages that extend beyond immediate visibility improvements:
First-Mover Advantage
Organizations that implement comprehensive schema early establish stronger knowledge graph connections and trust signals before competitors, creating durable visibility advantages that compound over time.
AI Citation Preference
Content with robust schema markup receives preferential treatment in AI citation patterns, establishing the organization as a primary information source within its industry.
Energy Efficiency Positioning
As AI energy constraints intensify, organizations with schema-optimized content will maintain visibility while competitors with unstructured content face increasing disadvantages.
Case Studies
Case Study 1: E-Commerce Schema Implementation
Company Profile
A mid-sized e-commerce retailer with 5,000+ products across 12 categories implemented comprehensive schema markup as part of a visibility enhancement initiative.
Implementation Approach
- Product schema with detailed specifications and variant data
- AggregateRating schema with verified review integration
- Organization schema with brand identity verification
- BreadcrumbList schema for navigation hierarchy
- FAQ schema for product-specific questions
Results
- 47% increase in product rich results within 60 days
- 32% higher click-through rate on product listings
- 22% improvement in average page dwell time
- 18% reduction in bounce rate
- 26% increase in conversion rate for schema-enhanced products
Key Learning
The combination of Product and AggregateRating schema created a powerful trust signal that significantly improved user engagement metrics. The implementation cost was recouped within 45 days through increased conversions.
Performance improvements following schema implementation
Case Study 2: B2B Content Publisher
Company Profile
A B2B technology publisher with 2,500+ articles and white papers implemented a comprehensive schema strategy to improve visibility in generative search.
Implementation Approach
- Article schema with detailed publication metadata
- Author schema with expertise and credential signals
- Citation schema linking to authoritative sources
- Organization schema with industry verification
- Dataset schema for research publications
Results
- 186% increase in AI search result citations within 90 days
- 42% higher inclusion rate in generative search responses
- 78% improvement in featured snippet appearances
- 36% increase in referring domains from AI-enhanced publications
- 54% growth in domain authority over 6 months
Key Learning
The author expertise signals created through schema markup substantially increased content authority in AI evaluations. The citation network effect created compounding visibility benefits over time.
AI citation growth following schema implementation
Case Study 3: Energy Efficiency Validation
Research Profile
A collaborative research project between a major search provider and university computer science department measured the energy impact of schema implementation at scale.
Methodology
- Processing comparison between structured and unstructured content
- Energy consumption measurement across 100,000 document samples
- Computational complexity analysis for entity extraction
- Token reduction measurement in AI processing pipelines
- Processing time benchmarking across different content types
Results
- 15.4% reduction in GPU cycles for content with comprehensive schema
- 27.8% lower energy consumption for entity extraction from structured data
- 42.3% reduction in token processing requirements
- 18.6% faster processing time for structured vs. unstructured content
- 35.9% more energy-efficient inference for schema-enhanced pages
Key Learning
The energy efficiency advantages of schema-structured content create significant economic incentives for search systems to prioritize such content, especially at web scale where small per-document savings compound into massive efficiency gains.
Energy efficiency comparison between structured and unstructured content
Frequently Asked Questions
Isn't schema markup just ornamentation for search results?
No, schema markup delivers substantial value beyond visual enhancements. Rich results lift organic click-through rates by 30-58%, which directly influences user behavior signals that impact rankings[6][31]. More importantly in the AI era, schema reduces computational overhead for search systems by providing pre-structured, machine-readable data that requires less energy to process.
Isn't schema maintenance too costly compared to the benefits?
While schema implementation does require initial investment and ongoing maintenance, the costs are minimal compared to the visibility benefits. More importantly, when compared with the $7 trillion data-center build-out projected by 2030[15], providing structured data is an extremely cost-effective way to ensure continued visibility as search systems optimize for energy efficiency.
Won't AI just figure out my content without schema anyway?
While AI systems can extract meaning from unstructured content, this approach is substantially more energy-intensive. As compute scarcity and emission caps constrain AI operations, brute-force NLP becomes economically untenable at scale[32][33]. Content that provides pre-structured data will inherently require less energy to process, creating a strong economic incentive for AI systems to prioritize such content.
Which schema types should we prioritize for implementation?
Priority should be given to schema types that establish entity identity and trust signals: Organization schema for company verification, Author schema for expertise signals, Product schema for commercial offerings, and FAQ schema for question-answer content. These core schema types provide the foundation for trust and visibility in AI-driven search environments.
How can we measure the ROI of schema implementation?
Key metrics for measuring schema ROI include: rich result impressions in Search Console, organic CTR improvements, featured snippet appearances, knowledge panel triggering, voice search result inclusion, and AI citation frequency. For e-commerce sites, conversion rate improvements on schema-enhanced product pages provide direct revenue impact measurement.
Is schema markup only relevant for Google, or does it impact other platforms?
Schema markup impacts visibility across multiple platforms with varying citation patterns. Our research shows ChatGPT favors Wikipedia (47.9%), while Perplexity prioritizes Reddit (46.7%). However, schema-enhanced content consistently improves visibility across all platforms by providing the structured data and trust signals that AI systems need for efficient, reliable information retrieval.
Implementation Roadmap
A successful schema implementation requires a strategic, phased approach that prioritizes high-impact elements while building toward comprehensive coverage. The following roadmap provides a practical guide for organizations of all sizes.
Phase 1: Foundation
(Months 1-2)
- Conduct comprehensive schema audit
- Implement Organization schema
- Deploy core Author schema
- Add WebSite and WebPage schema
- Establish schema validation process
- Configure monitoring baseline
Phase 2: Expansion
(Months 3-4)
- Implement Article/BlogPosting schema
- Add Product schema (if applicable)
- Deploy FAQ schema for key questions
- Implement BreadcrumbList schema
- Add Review and Rating schema
- Establish entity relationship mapping
Phase 3: Optimization
(Months 5-6)
- Implement HowTo schema (if applicable)
- Add Dataset schema for research content
- Deploy Event schema (if applicable)
- Enhance citation connections
- Implement schema automation
- Develop ongoing optimization plan
Key Implementation Considerations
Technical Considerations
-
Implementation Method:
Use JSON-LD in the document head for optimal processing efficiency.
-
Validation Tools:
Implement automated validation using Google's Rich Results Test tool and Schema.org's validator.
-
CMS Integration:
For dynamic content, integrate schema generation into content management workflows.
-
Monitoring Setup:
Configure Google Search Console to track rich result performance and crawl stats.
Organizational Considerations
-
Team Responsibilities:
Define clear ownership between technical and content teams for schema maintenance.
-
Content Guidelines:
Create content creation standards that support schema requirements.
-
Schema Governance:
Establish review processes to maintain schema accuracy and completeness.
-
Performance Review:
Schedule quarterly assessment of schema impact on visibility metrics.
Timeline and Resource Allocation
| Implementation Phase | Timeline | Key Resources | Expected Outcomes |
|---|---|---|---|
| Initial Assessment | 2-3 weeks | SEO specialist, developer | Schema audit, prioritization plan |
| Foundation Implementation | 4-6 weeks | Developer, content strategist | Core entity schema deployment |
| Expansion Phase | 6-8 weeks | Developer, content team | Content-type specific schema implementation |
| Validation & Testing | 2-3 weeks | QA specialist, SEO analyst | Error correction, validation confirmation |
| Optimization & Monitoring | Ongoing | SEO specialist, analytics team | Performance tracking, incremental improvements |
Key Takeaways
"The economics of AI computation is creating a new visibility paradigm where structured data is no longer optional—it's essential for sustainable search presence."
– Oregon Coast AI Analysis, 2025
"Schema markup reduces AI processing costs by up to 15% through pre-defined entity boundaries, creating an economic incentive for search systems to prioritize structured content."
– Schema Implementation Research Consortium
"As AI systems optimize for energy efficiency and factual reliability, content with comprehensive schema markup will receive disproportionate visibility advantages."
– Oregon Coast AI Energy Analysis
"The ROI of schema implementation is compelling: 30-58% higher CTR, 42% increased AI citation frequency, and significant competitive advantages in generative search visibility."
– Schema Visibility Impact Study, 2025
"Organizations that implement schema strategically now will establish trust and efficiency signals that create compounding visibility advantages over time."
– Oregon Coast AI Strategic Forecast
Conclusion and Next Steps
Schema markup may not carry a hardcoded weight in Google's core algorithm today, but the economic physics of AI, the energy crisis of ever-larger models, and the rising premium on trustworthy information are converging to make structured data indispensable. Markup reduces crawl cost, feeds verifiable knowledge graphs, and supplies the trust "credit" that next-generation search engines must reference. In practice, using schema is no longer optional—it is the price of admission to a sustainable, AI-driven web.
The organizations that implement comprehensive schema strategies now will establish the trust and efficiency signals that create durable visibility advantages. As AI systems increasingly optimize for computational efficiency and factual reliability, structured content will inherently receive preferential treatment in search results and generative responses.
Strategic Recommendations
- Begin with a comprehensive schema audit to establish baseline and priorities
- Implement trust-focused schema types first: Organization, Author, Article
- Develop a phased rollout plan that aligns with content priorities
- Establish robust validation and monitoring processes
- Create systematic schema governance to maintain quality
- Track ROI through visibility metrics and conversion impact
Action Plan Timeline
- Immediate (Next 30 Days): Conduct schema audit and prioritization
- Short-Term (60-90 Days): Implement core identity and trust schemas
- Medium-Term (3-6 Months): Deploy content-specific schema across site
- Long-Term (6-12 Months): Develop comprehensive trust credit system
Future Outlook
Generative search will amplify schema's utility. SGE already calls structured data directly in answer panels, citing sources to offset hallucination risk[10]. Looking ahead, governments may mandate provenance markup for high-risk content (health, finance) to comply with AI transparency rules, making schema de facto compulsory.
Organizations that position themselves at the forefront of structured data implementation will not only ensure continued visibility in the AI-driven search landscape but will also establish themselves as trusted information sources that AI systems preferentially reference. In the physics-of-AI era, schema markup is evolving from a technical optimization tactic to a fundamental business strategy for sustainable digital presence.
About the Author
Ken Mendoza
Ken Mendoza holds a bachelor's degree in political science and microbiology from UCLA, with graduate work at Cornell University. As a leading researcher at Oregon Coast AI, Ken specializes in the intersection of structured data implementation, AI energy economics, and search visibility optimization.
With over a decade of experience in AI systems and search optimization, Ken has led research initiatives examining citation patterns across 41M+ AI search results, 30M+ citation patterns, and 75K+ brand studies to identify the evolving requirements for visibility in generative search environments.
AI Disclosure Statement
This white paper was developed with the assistance of advanced AI tools in accordance with industry best practices for transparency and intellectual integrity. While leveraging AI capabilities for research synthesis, data analysis, and editorial enhancement, all substantive content, methodologies, strategic insights, and core recommendations represent the expert knowledge and professional judgment of the named authors.
Our AI-augmented development process included research acceleration and pattern identification across industry data, statistical analysis validation and visualization, editorial consistency and readability optimization, and citation verification and formatting. This disclosure reflects our commitment to transparent innovation and responsible AI utilization in professional communications.
About Oregon Coast AI
Oregon Coast AI is a leading research and consulting organization specializing in generative engine optimization (GEO), multi-personality website architecture, and advanced schema implementation. Our team of PhD-level experts works with enterprise organizations to develop visibility strategies that maximize discovery and engagement across AI-powered search and recommendation systems.
References and Citations
[1] Safari Digital - Schema Markup an SEO Ranking Factor
[2] SEO Roundtable - Google Structured Data Ranking
[3] Google Developers - Introduction to Structured Data
[4] Google Developers - Search Gallery
[5] Schema App - Common Questions About Schema Markup for SEO
[6] Tassos - How to Get Rich Results
[7] AdLift - What is Schema Markup
[8] Schema App - How to Implement Schema Markup to Increase E-E-A-T
[10] Search Engine Land - How Schema Markup Establishes Trust
[11] MIT News - Explained: Generative AI Environmental Impact
[12] ACM - The Energy Footprint of Humans and Large Language Models
[13] BNEF - Power for AI: Easier Said than Built
[14] The Verge - AI Data Center Energy Forecast
[15] McKinsey - The Cost of Compute: A $7 Trillion Race
[16] NPR - Artificial Intelligence's Thirst for Electricity
[17] SprinkleData - What is Structured Data
[18] Google Support - Knowledge Panel
[19] Search Engine Journal - Google E-A-T and Structured Data
[20] arXiv - Bayesian Credible Intervals for Triple Accuracy
[21] arXiv - Uncertainty-aware Reasoning Modules
[22] FirstEigen - What is a Data Trust Score?
[23] ERIC - Trust Scores for Datasets
[24] KC Web Designer - Implement Google E-E-A-T Website Schema Markup
[25] E-E-A-T Minds - Schema Markup Best Practices
[26] arXiv - Hard-coded Entity Boundaries
[27] OpenReview - Graph-Matching Complexity Reduction
[28] SchemaWriter - Does Schema Improve Google Rankings?
[29] Sixth City Marketing - Schema Markup Statistics & Facts